 Image credit: Pxfuel
Image credit: PxfuelLoading multiple csv files in Stata
How to load endless csv files into Stata with the loop function instead of copy/pasting yourself to death.
The Problem
One of my colleagues had a pretty common data problem: How to load around 200 individual csv-files (comma separated files) into Stata?
There were approx. 100 patients and each patient had 2 csv-files containing different scans. He could of course manually copy/paste the contents from file into a single excel file and then load the combined file into Stata. While it is completely possible to do, it is repetitive, boring and there is a high risk of making manual errors.
No thanks. Life already offers plenty of repetitive and boring monkey work.
Table of Contents
The Solution
We use Stata’s mighty loop function to do the copy-pasting for us. We’ll do that in 3 steps:
- Define csv files to include
- Loop over files to import and append each file
- Export final data set
You can download the csv- and Stata Do-file from the example here if you want to run it yourself.
Data structure
Each patient had 2 csv-files that each looked somewhat like this:
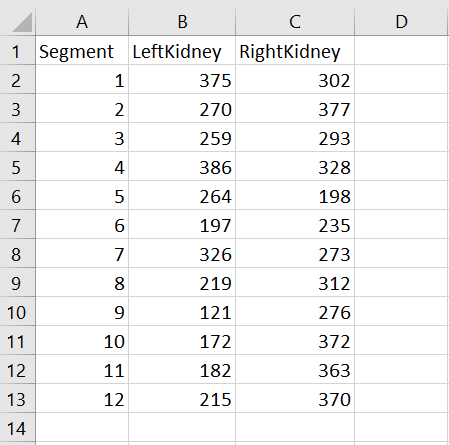
All csv-files were stored in a single folder and systematically named: [ID number]-data-1.csv and [ID number]-data-2.csv: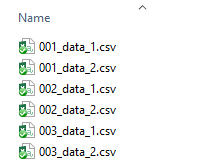
Step 1 - Define csv files
First we need to define which files to include. Assuming you have your do file in the same folder as all the csv-files, then we want all csv files from the “current” folder (the folder that Stata is working in). We’ll first define a local with the path to the current folder, which Stata stores under the name c(pwd).
local filepath = "`c(pwd)'" // Save path to current folder in a local
di "`c(pwd)'" // Display path to current folder
Next, we want to store a list with the names of all csv files in the folder that we want to import. We’ll store this list in a local as well.
local files : dir "`filepath'" files "*.csv" // Save name of all files in folder ending with .csv in a local
di `"`files'"' // Display list of files to import data from
Step 2 - Loop over files
To actually import the files listed in the files local, we’ll do a couple of things
First, we will generate a temporary file called master.
tempfile master // Generate temporary save file to store data in
save `master', replace empty
Note: The name of the tempfile is not important, this is simply where we will store the data while running our code.
Next, we will ask Stata to run a loop (i.e. run the same code several times) for all files stored in the local files. The loop consists of two parts: A, where each csv file is imported (import delimited) and B, where that file is added (append) to bottom of the master file. To keep track of which observations belong to which patients, we generate a variable id in part A containing the name of each imported csv file.
foreach x of local files {
di "`x'" // Display file name
* 2A) Import each file and generate id var (filename without ".csv")
qui: import delimited "`x'", delimiter(";") case(preserve) clear // <-- Change delimiter() if vars are separated by "," or tab
qui: gen id = subinstr("`x'", ".csv", "", .)
* 2B) Append each file to masterfile
append using `master'
save `master', replace
}
Run this code, and voila! You have combined all 200 (or 200,000) files in the blink of an eye. Only thing left is to export the data.
Note: If your final dataset only contains the variables id and v1, then it is because the variables in your csv files are separated by something other than semicolons. Use browse to inspect the data to see if it is spaces, tabs, commas or something else and correct the delimited() option above. Type help import delimited or db import delimited to read more.
Step 3 - Export final data set
If you are used to Stata, then exporting the final data set is pretty straight forward.
order id, first
sort id
save "csv_combined.dta", replace
Final remarks
Hope this introduction to the loop and dir commands has helped. Naturally, the same principles can be used for other file types and much more complex tasks.
Other examples of use:
- Importing txt-files (same principle as csv files above but change
dirandimport delimitedto new file format) - Importing pdf-files (use DocuFreezer to batch convert pdf files to txt files and same as above)
- Convert individual csv data files to individual Stata files (simply add
save "newfilename.dta", replacein bottom of loop) - Copy csv files from many different folders into a single folder using
copyandshell(a bit more advanced, see this post on Statalist)